
Глубокое машинное обучение и системы искусственного интеллекта в наше время являются очень популярными направлениями. Но современные процессорные архитектуры для задач подобного рода подходят далеко не лучшим образом, поэтому всё больше и больше разработчиков микроэлектроники обращаются к альтернативным и специализированным дизайнам. В гонку за искусственным интеллектом включился и такой японский гигант как Fujitsu — компания объявила о том, что ведёт работы над созданием специализированного процессора. Проект носит кодовое имя DLU (Deep Learning Unit), что в полной мере раскрывает его предназначение. Основной целью проекта является достижение десятикратного преимущества над конкурирующими решениями по соотношению «производительность на ватт». В разработке DLU находится с 2015 года, но лишь в этом году стали известны некоторые подробности об архитектуре нового процессора Fujitsu.

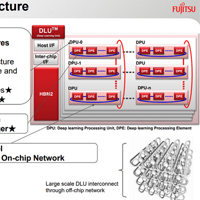
Глава отдела разработок ИИ, Такуми Маруяма (Takumi Maruyama), отметил, что архитектура DLU активно использует вычисления со сравнительно низкой точностью, как это делают и многие другие чипы, предназначенные для глубокого машинного обучения. Это позволяет добиться оптимального соотношения производительности и потребляемой мощности. Чип DLU поддерживает форматы FP32, FP16 INT16 и INT8, и компания продемонстрировала, что даже целочисленные 8 и 16-битные форматы могут эффективно использоваться в ряде задач машинного обучения без серьёзных проблем, вызванных низкой точностью вычислений. Архитектура Fujitsu DLU спроектирована таким образом, чтобы быть полностью управляемой со стороны программного обеспечения. Процессор разбит на блоки DPU (Deep Learning Processing Units), их общее количество может быть разным, но каждый блок DPU состоит из 16 более простых блоков DPE (Deep Learning Processing Elements).

В свою очередь, каждый DPE состоит из восьми блоков исполнения SIMD-инструкций и большого набора регистров. Последний, в отличие от традиционных кешей, полностью управляем программно. В состав чипа также входит некоторый объём памяти HBM2, которая выступает в роли кеша, а также интерфейсы межпроцессорной шины Tofu. Последняя позволяет объединять массив DLU в единую сеть с развитой топологией. Структура этой сети приведена на слайде выше. Как обычно, специализированные процессоры, к числу которых относится и Fujitsu DLU, работают в тандеме с процессорами общего назначения. В данном случае компания планирует использование чипов с архитектурой SPARC, что неудивительно — именно Такуми Маруяма принимал самое активное участие в разработке этой архитектуры начиная с 1993 года. Первый выход DLU на рынок запланирован на 2018 год, именно в виде сопроцессора, но у Fujitsu имеются и планы по интеграции данной архитектуры в ЦП общего назначения с архитектурой SPARC. Соперниками новинки будут чипы Intel Lake Crest, ускорители Radeon Instinct, а также чипы NVIDIA. Последняя имеет неплохую фору в сфере машинного обучения и конкурировать с ней будет непросто.
Источник: ServerNews
Добавить комментарий